
Небольшое исследование об отображении кириллического текста в dicom-элементах типа Code String (CS). Не всё так просто, как оказалось. Инструкцию читать надо! 🙂
Один из пользователей программы Dicom AutoExport версии 1.9.1 прислал несколько файлов с указанием того, что кириллица в тегах такого типа все-равно неправильно отображается после конвертации.
Что выяснилось? А оказалось, что тип кодировки, указанный в элементе (0008,0005) совершенно не влияет на отображение символов в элементах Code String.
В стандарте Dicom он определяется как строка символов длиной не более 16 байт, которая может содержать прописные буквы, цифры 0-9, пробел и нижнее подчеркивание. Кодировка символов в стандарте не указана, но вот на одном из сайтов нашёл, что она должна быть ASCII, и понятно, что латиница. Откуда они взяли, что должно быть именно ASCII непонятно, но, по-видимому, многие вьюверы ожидают именно её.
Взял, что было под рукой из вьюверов. Оказалось, что это Microdicom, Weasis и Радиант. Dicom-файл "сделан" на аппаратуре и ПО компании Телеоптик, программой экспорта кодировка всех текстовых тегов, в том числе и CS, конвертирована в UTF-8.
Microdicom и weasis однозначно не опознают здесь УТФ8.
То, что там УТФ я убедился через онлайн-конвертер.
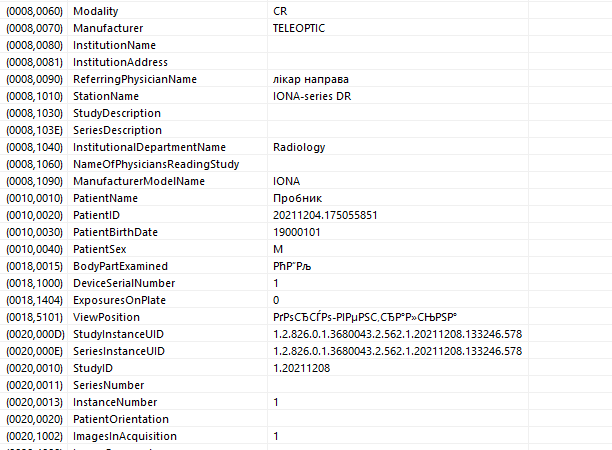
А Радиант нормально всё видит.
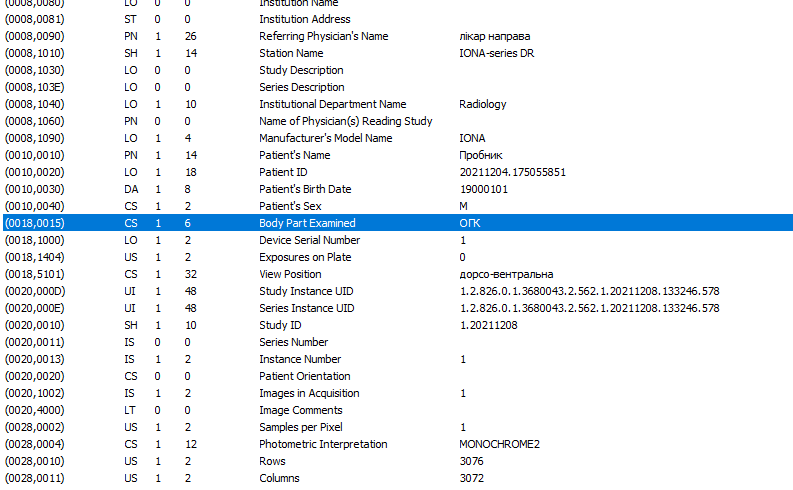
Есть ещё один нюанс.
DicomDump указывает, что ошибка также в том, что значения тегов взяты не из словаря, т. е. не соответствуют стандарту.
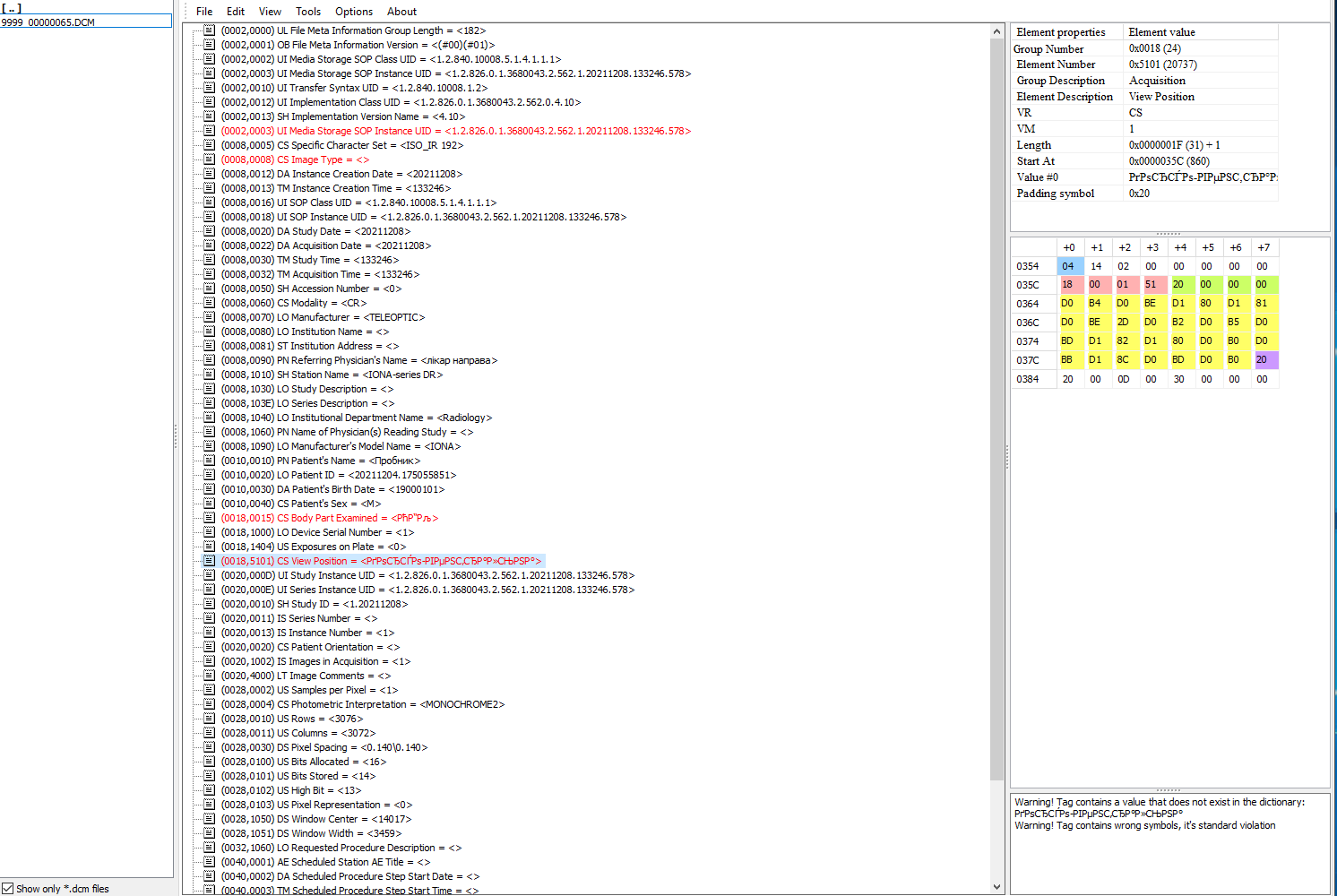
Например, для (0018,5101) это должны быть двух-трехбуквенные значения, обозначающие позицию пациента: https://dicom.innolitics.com/ciods/cr-image/cr-series/00185101
А для (0018,0015) есть приложение "L" в стандарте с перечислением возможных значений: https://dicom.nema.org/medical/dicom/current/output/chtml/part16/chapter_L.html#chapter_L
Я не думаю, что те вьюверы, которые неправильно отображают Юникод в этих тегах, ориентируются на стандартные значения из словаря и типа кроме них ничего не умеют видеть.
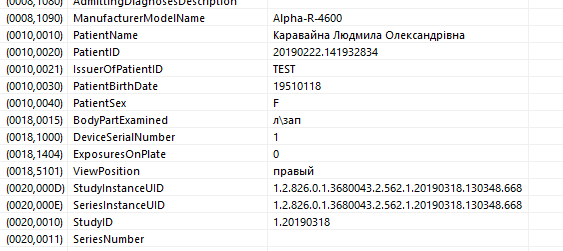
Начал экспериментировать. Взял аналогичные файлы, где все теги в кодировке 1251 и всё, кроме CS конвертировал в UTF-8. Т.е. (0018,0015) и (0018,5101) остались в кодировке win-1251.
Теперь MicroDicom все отображает корректно:
А Weasis все-равно не понимает кириллицу в CS:
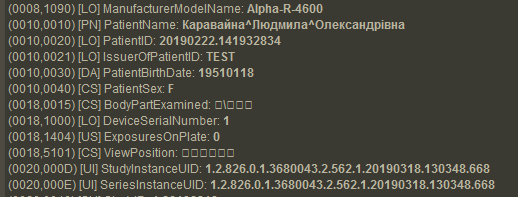
И Радиант перестал правильно смотреть:
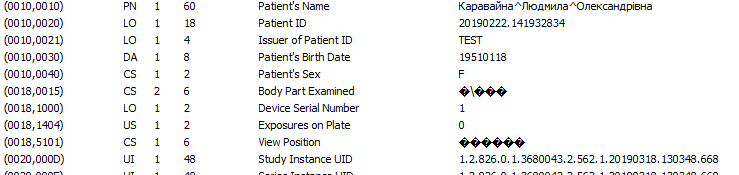
Т.о. вывод:
Первый вьювер в этих тегах читает кодировку в вин-1251, второй — непонятно, что ждет, а Радиант ждет то, что указано в (0008,0005).
Добавил функцию конвертации из 1251-ansi в ascii и применил ее только к тегам CS.
Т.е. всё в UTF-8, а CS в ASCII
Теперь MicroDicom показывает какую-то хрень, а точнее пытается ascii отобразить как 1251:
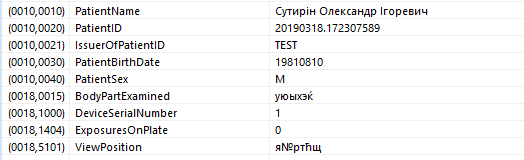
Weasis все равно кириллицу не видит:
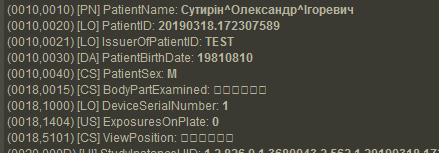
И Радиант тоже:
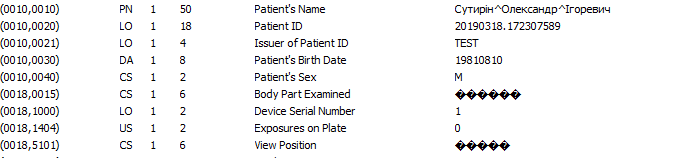
Вывод: Нет одного единого подхода у вьюверов при отображении этих тегов. Единственный вариант, когда все вьюверы не отображают иероглифы в этих тегах — латиница. Т.е., чтобы всех удовлетворить, нужно CS записывать латиницей, а ещё лучше конкретные значения брать из словаря.
Для (0018,5101) в «людской» рентгенографии это всего-то восемь возможных значений: AP, PA, LL, RL, RLD, LLD, RLO, LLO. Для ветеринарии, конечно, посложнее 🙂 и для лаборанта там вообще китайская грамота будет. Но, наверное, стоит эти значения жестко занести в список для выбора без возможности его редактирования.
Для (0018,0015) всё ещё сложнее. Укладок хренова туча и все их проблематично внести. А если даже они и будут доступны для выбора, то кто же их выбирать будет, когда мало кто из персонала смыслит в этих названиях. Когда укладка выбирается на графическом шаблоне, то лаборанты ещё справляются как-то, а выбрать из списка непонятных слов на латинице — это нереально 🙂
В версии 1.9.3 программы Dicom AutoExport была добавлена для элементов типа Code String была специально добвлена опция, определяющая, каким образом их обрабатывать.