Одним из самых компьютеризированных разделов медицины является радиодиагностика. Медицинские исследования генерируют большое количество данных, которые затем обрабатываются передовыми методами визуализации, 3D-реконструкции по срезам и даже машинного обучения. Этот топик призван помочь системным администраторам погрузиться в тематику передачи и хранения медицинских изображений.
Авторские права на данную статью принадлежат Владиславу Россу - gag_fenix . Она была недавно опубликована на популярном у программистов, админов и широкого круга околокомпьютерной публики веб-сайте — https://habr.com/ru/post/217761/ А здесь публикуется с любезного разрешения её автора с некоторыми сокращениями и моими комментариями.
Фото автора
Техминимум
DICOM (Digital Imaging and Communications in Medicine) — стандарт обработки, хранения, передачи, печати и визуализации медицинских изображений. DICOM определяет формат файлов радиологических исследований и сетевой протокол, который в качестве транспорта использует TCP/IP. DICOM разрабатывается с 80-х годов, ежегодно обновляется, став на сегодняшний день стандартом де-факто — поддерживается всеми современными цифровыми устройствами: томографами, УЗИ-аппаратами, маммографами, рентгеновскими аппаратами и т.д.
Основная «фишка» DICOM — интероперабельность. За счет различных механизмов DICOM позволяет передавать данные между очень разным медицинским оборудованием и ПО.
Сама спецификация протокола интересна в первую очередь разработчикам медицинского софта. Мы рассмотрим основные моменты, касающиеся эксплуатации с точки зрения ИТ-отдела, не углубляясь в дебри.
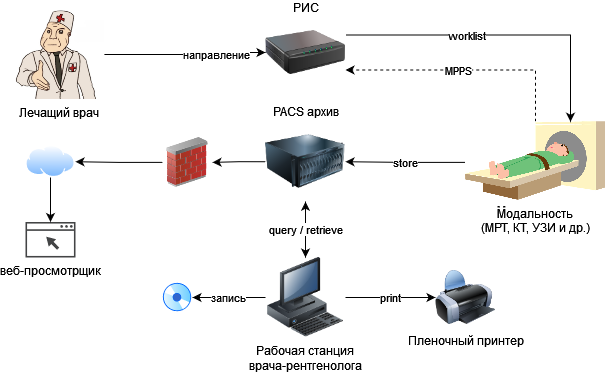
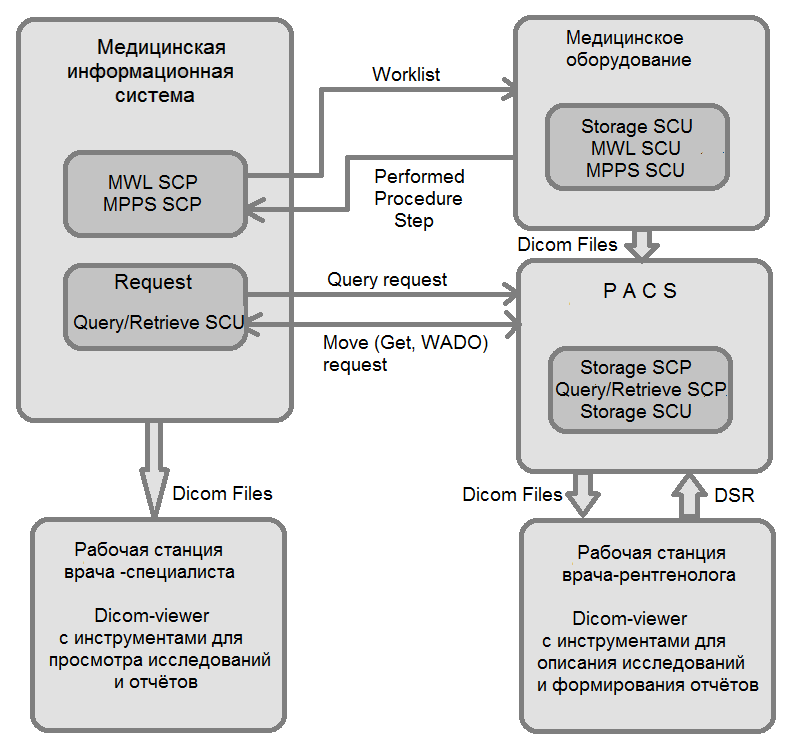
Информация о пациенте и запланированном исследовании поступает на аппарат из радиологической информационной системы. По завершении диагностики аппарат уведомляет РИС и отправляет снимки в центральный архив. Рентгенолог получает снимки на рабочую станцию (со специально откалиброванным монитором) и составляет заключение. Пациенту файлы исследования могут быть записаны на диск или распечатаны.
Основные понятия
Modality (модальность) — медицинский аппарат, создающий (acqusition) медицинское изображение определенного типа. Типы обозначаются аббревиатурой, например:
PACS — Picture Archiving and Communication System — центральный сервер хранения медицинских изображений в организации, который получает исследования от модальности и по запросу выдает на рабочие станции радиологов или в другие отделения. Может быть интегрирован с RIS и/или HIS;
HIS — Hospital Information System — медицинская информационная система (МИС) — общая система электронного документооборота мед. учреждения;
RIS — радиологическая информационная система (РИС) — система информатизации диагностического отделения, содержащая данные от пациентов, расписание приёма на исследование и т.д.
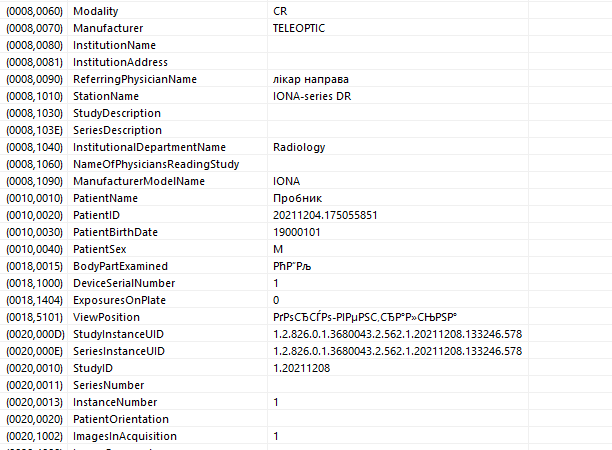
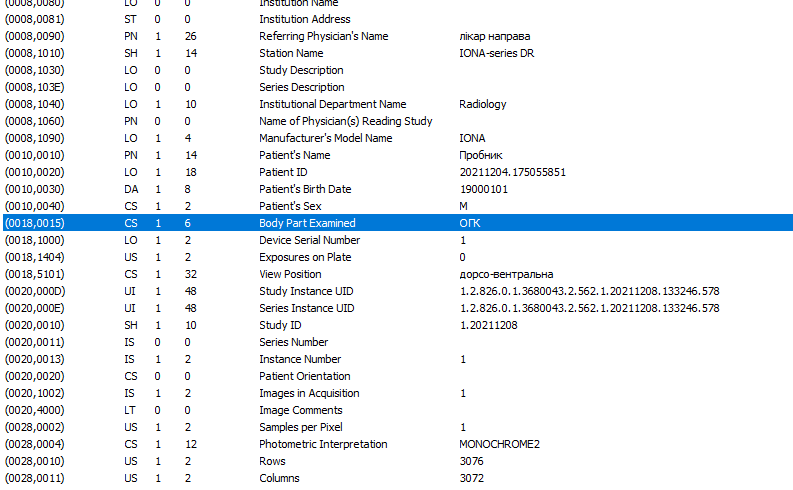
DICOM-файл — файл (стандартное расширение .dcm), содержащий графическую информацию, а также метаданные. Для большинства модальностей в одном файле хранится единственное изображение, но иногда это может быть серия кадров. Используются различные алгоритмы сжатия: Lossy JPEG, JPEG2000 или Loseless JPEG. Также DICOM поддерживает хранение waveform данных (ЭКГ, аудио).
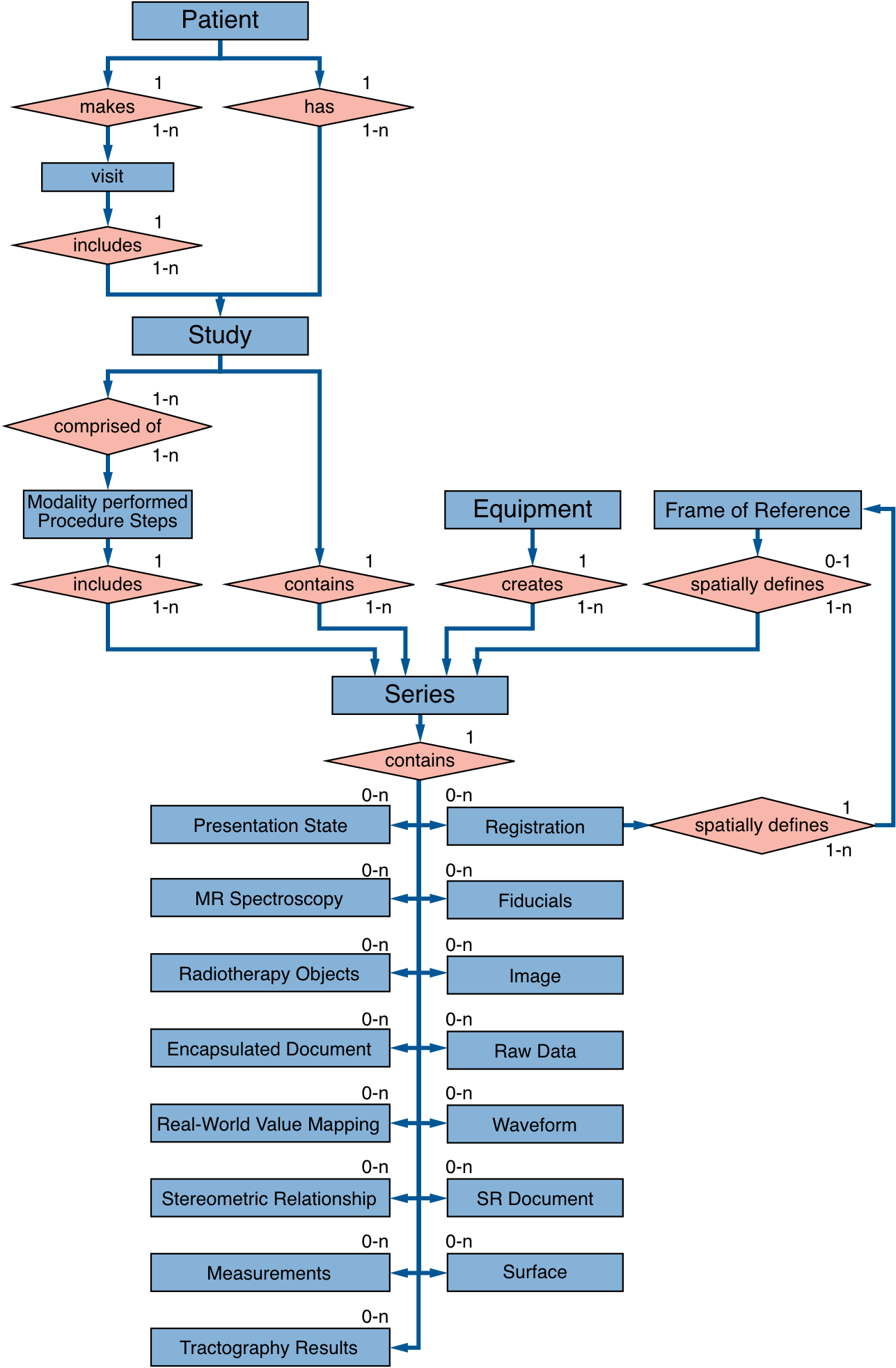
Файл является нижним элементом иерархии: пациент (patient) → исследование (study) → серия (series) → изображение (image/instance).
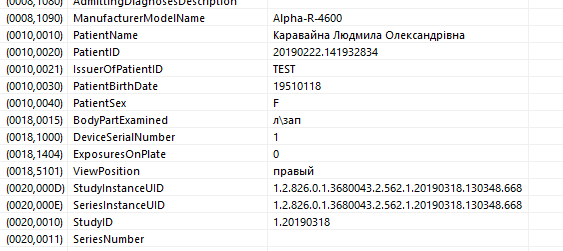
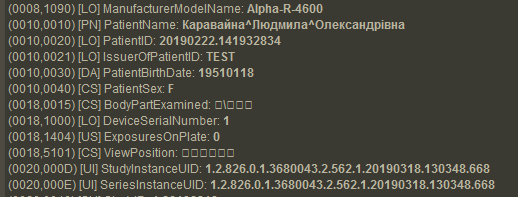
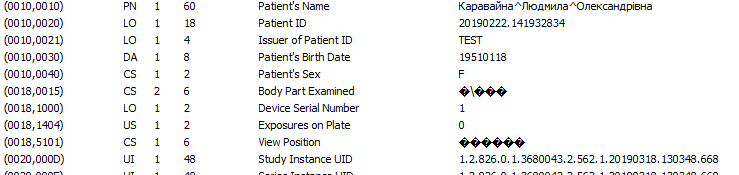
В тегах каждого файла хранятся атрибуты с информацией о самом изображении, а также об объектах верхнего уровня, в т.ч.:
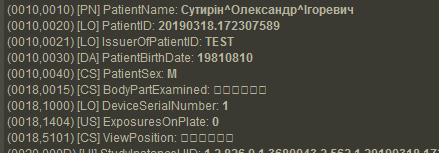
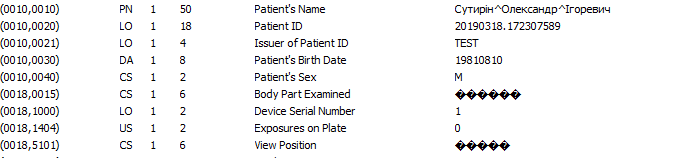
- patient demographics — персональные данные пациента: ФИО с разделителем кареткой (??????^????^?????????), возраст: число и буква (0???), пол (M/F/O), вес и т.д.;
- уникальный идентификатор (UID) study и series по ISO 8824;
- patient ID;
- модальность;
- сведения о медицинском учреждении, ФИО радиолога;
- дата и время обследования;
- марка и модель аппарата;
- другая информация об исследовании; полный список можно посмотреть тут.
Анонимизация (anonymize) — функция удаления персональных данных из DICOM-файлов;
DICOMDIR — файл с метаинформацией о снимках в папке. Используется при записи снимков на CD/DVD;
SCU (Service Class User) и SCP (Service Class Provider): в терминологии DICOM SCU инициирует запрос, а SCP предоставляет ему сервис. Иначе говоря, SCU — клиент, а SCP — сервер. При этом один и тот же узел DICOM может быть в каких-то случаях SCU (например, когда он запрашивает список), а в каких-то SCP (когда получает снимки);
AE — Application Entity — отдельный сервис DICOM. В простом случае на физическом устройстве (станции, PACS, модальности) «живет» один AE, но по стандарту их может быть и несколько, в т.ч. на одном TCP-порте;
AE Title — название узла (AE), уникальное в сети, до 16 символов ASCII, обычно заглавными. Бо́льшая часть DICOM-софта работает в режиме whitelist, т.е. обмен данными разрешается только с AE, заранее занесенными в список. Как правило, для успешной передачи снимков на обоих сторонах в ПО нужно указать IP, порт и AE Title;
IOD — Information Object Definition — шаблон, определяющий список атрибутов для объектов реального мира. Для атрибутов задается тип данных, длина и флаг множественности. Для повторного использования атрибуты группируются в модули. Например, атрибут Patient's Birth Date входит в модуль Patient, который используют разные IOD. Если IOD содержит модули для нескольких объектов, он называется композитным (composite). Например, IOD снимка томографа содержит не только само изображение, но также наследует информацию о пациенте, исследовании, серии, frame of reference и оборудовании. IOD и команда комбинируются в SOP Class (Service Object Pair), например, класс «CT Storage» — это комбинация команды C-Store и КТ-изображения. Подробно останавливаться на модели данных DICOM мы не будем; отсылаю интересующихся к литературе в конце.
Transfer syntax — режим кодирования информации при передаче, задает порядок бит implicit/explicit little/big endian, формат сжатия графики. Иногда его приходится указывать явно;
Association — процесс установления сетевой сессии в DICOM; подразумевает обмен информацией о поддерживаемых Abstract и Transfer syntax. Ошибка на этапе Association говорит либо о неверных настройках TCP или AE Title либо о несовместимом Transfer syntax или неподдерживаемом/отключенном в софте SOP;
DICOMweb — стандарт REST-API для просмотра снимков через web.
Сервисы DICOM
Сервисы DICOM обеспечивают взаимодействие модальностей, PACS, RIS и рабочих станций по сети, поддерживая набор композитных операций над объектами (DIMSE):
C-STORE — отправка снимков с SCU на SCP («пуш»), например, с аппарата в архив;
C-GET — получение снимков от SCP на SCU («пулл»), например, из архива на рабочую станцию;
C-FIND — поиск исследований по атрибутам (например, ФИО пациента, дате и др.);
C-MOVE — запрос от SCU на отправку снимков с SCP на какой-то третий хост (который может быть самим SCU); SCP должен «знать» AE Title хоста назначения;
C-ECHO — проверка связи («пинг»).
Подробнее об операциях DICOM можно почитать в топике [6].
Сервис Query/Retrieve (Q/R) комбинирует C-FIND и C-MOVE (реже C-GET) для поиска объектов на SCP с последующим получением на SCU.
Сервис Storage предназначен для согласования и передачи объектов от SCU к SCP с помощью команды C-STORE. При этом на принимающей стороне (SCP) может производиться процесс добавления/изменения информации Coercion, если какие-то из обязательных атрибутов не заполнены, например автоматически генерироваться Patient ID.
Modality Worklist (MWL) — предварительное получение информации о пациенте, для которого запланировано исследование, из RIS на модальность. Таким образом, специалист, проводящий исследование, избавляется от необходимости заполнять эту информацию вручную, что экономит его время и уменьшает количество ошибок.
MPPS (Modality Performed Procedure Step) — фиксация статусов проведенных исследований, количества изображений, полученной дозы радиации и т.п. в RIS.
Print — печать hard copy снимка на пленочном принтере.
Администрирование DICOM
PACS-сервер
В самом примитивном случае никакого центрального сервера вообще нет. Снимки с аппаратов сыпятся на рабочие станции, а врачи гоняют их между компьютерами в одноранговой сети. Такой подход по понятным причинам является тупиковым.
Необходимо выделение центрального архива — PACS, который будет круглосуточно обеспечивать доступ к полному собранию обследований. Если выбор PACS лежит на ИТ-отделе, стоит обратить внимание на бесплатные проекты:
- dcm4chee — open-source PACS на Java с web-интерфейсом. Работает на Linux, Mac OS X или Windows.
- Orthanc — легковесный и быстрый open-source mini-PACS под Linux, Mac OS X или Windows, написанный на С++. Поддерживает REST API и систему плагинов;
- Dicoogle — еще один кроссплатформенный open-source PACS;
- microsoft/dicom-server — облачное решение от Microsoft, можно развернуть локально в Docker, но, кажется, что оно заточено под небесплатный Azure;
- PacsOne — freeware (до 1 млн. снимков) PACS для Windows/Mac/Linux;
Из перечисленных PACS я работал только с dcm4chee (но на всех трёх платформах). По своему опыту могу сказать, что он способен обслуживать крупные архивы, а для конфигурирования доступна масса параметров — в Tomcat и XML-файлах. К сожалению, не все из них хорошо задокументированы, поэтому приходилось обращаться за помощью на форум.
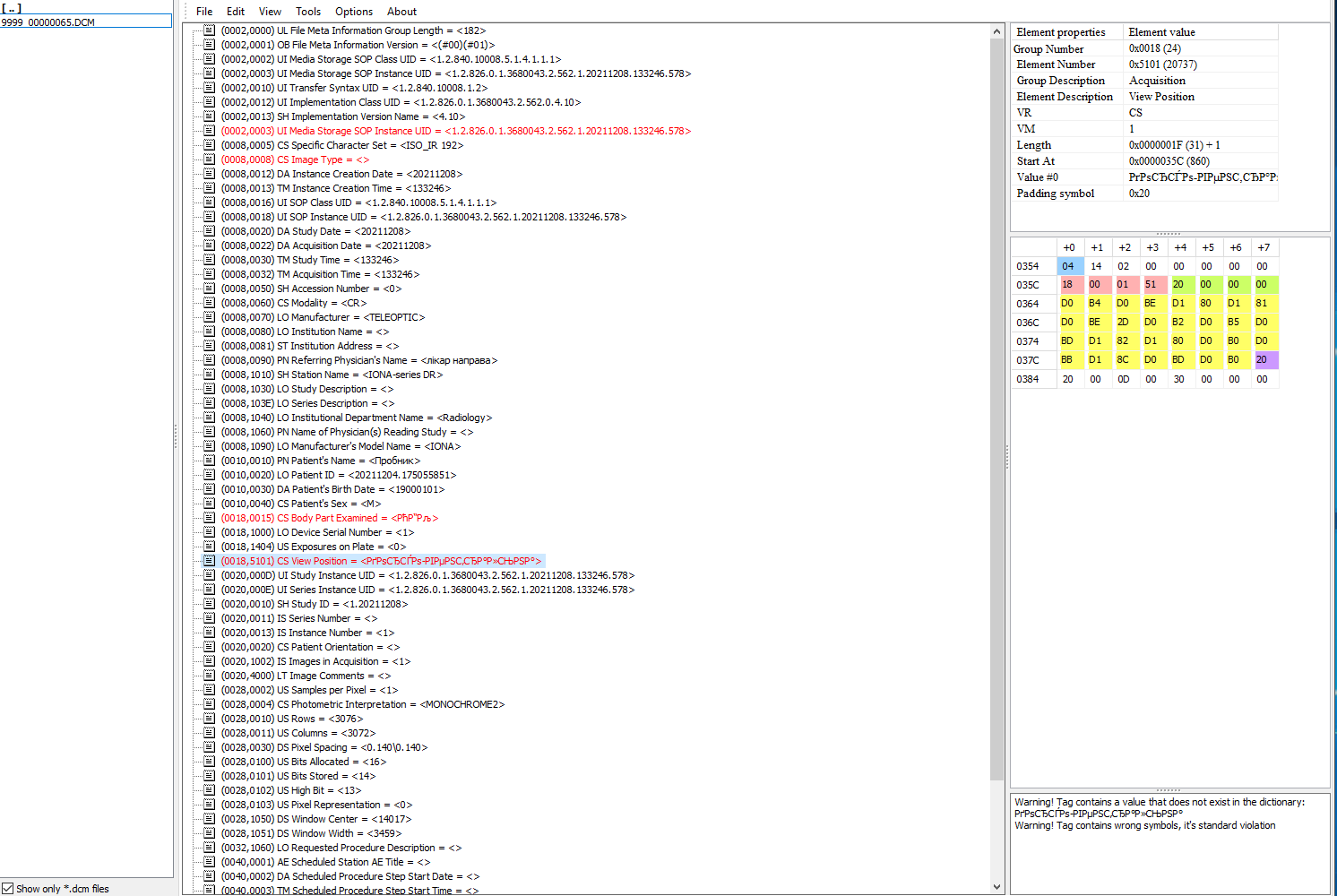
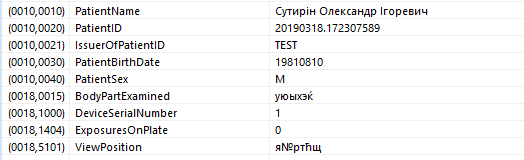
Финальным шагом автоматизации является интеграция PACS с RIS/HIS с реализацией MWL и MPPS. Без интеграции с общей системой архив PACS быстро превращается в «кашу»: данные пациента вводят на аппарате непосредственно перед исследованием, поэтому нет сквозного ID пациента, а ФИО часто заводится транслитом (*т. к. аппаратура, производящая снимки, использует нестандартную для Dicom кодировку символов кириллицы. Например, win-1251. Для исправления кодировки в таких файлах существует программа Dicom AutoExport . Прим. Александра Кузнецова — А.К.). В результате потом невозможно автоматически сопоставить исследование и историю болезни: например, Юлия Жукова из общей HIS может числиться в PACS как Yuliya Zhukova, Julia Jukova или даже Iulia Dzukova. До кучи появляются опечатки. Если же на аппарат будут автоматически приходить данные пациентов из RIS/HIS, то такой проблемы не возникнет.
Сеть
Пропускная способность сети должна быть не ниже 1 Гбит/c. Используйте выделенную локальную сеть, лучше всего физически изолированную от других сетей и Интернет или хотя бы в отдельном VLAN. Для увеличения скорости и надежности подключения PACS-сервера можно использовать bonding.
Что может затруднить задачу построения сети для радиологии: файрволлы или трансляция адресов между модальностями/станциями, динамические адреса, динамическое назначение порта в операции C-GET.
Стандартные TCP-порты DICOM: 104, 11112, 2762 (TLS).
Хранилище
Основная нагрузка на аппаратное обеспечение PACS ложится на диски.
Хранилище необходимо проектировать, исходя из двух параметров:
а) Необходимого интервала хранения архива. (*Для разных категорий исследований устанавливаются разные сроки храненения — от трех до десяти лет, и даже пожизненно— для некоторых видов патологий. Прим. А.К).
б) Количества поступающих новых данных в единицу времени. Эта величина сильно зависит от количества и типов оборудования, а также режима работы конкретного ЛПУ. (*Обычно самый большой размер имеют ангиографические исследования (видео), затем МРТ и КТ (много срезов), флюороскопия (многокадровые серии), маммография (т. к. изображения имеют высокое разрешение), затем рентгенография. Всё остальное «весит» значительно меньше. Прим. А.К.)
Таким образом, главной головной болью администратора является построение относительно большого по объему хранилища с высокой степенью надежности. Требования же к пропускной способности и IOPS не столь существенны, если клиентов (модальностей и рабочих станций) не очень много. В большинстве случаев подойдут обычные (СMR) жесткие диски (кажется, что диски с черепичной PMR записью плохо подходят для DICOM, но у нас опыта с ними не было). Однако современные PACS при желании позволяют организовать и многоуровневое хранилище, например: свежие снимки на SSD → архив на HDD → «холодный» архив на ленте или S3.
Если сервер, который выделили под PACS, не может вместить необходимое количество дисков (например, он одноюнитовый), решением может стать закупка СХД или дисковой полки, подключаемой к серверу.
Тут нужно отдельно отметить, что PACS, как правило, ведут реляционную базу данных с пациентами, исследованиями и снимками. Вот её, возможно, стоит хранить на быстром хранилище на SSD или HDD RAID0, чтобы ускорить Q/R поиск по большому архиву.
Обеспечение надежности и резервное копирование
Как следует из предыдущего пункта снимки нужно хранить до 10 лет, а рядовой жесткий диск может прожить значительно меньше. Стандартным способом увеличения надежности является использование RAID-массива. Если позволяет бюджет, то для обеспечения наилучшей производительности рекомендуется использование уровня RAID10, которые требует х2 пространства хранения и выдерживает отказ, как минимум, одного диска. Более бюджетным, но менее производительным является уровень RAID6, который выдержит отказ двух дисков. Уровни RAID0 и RAID5 использовать не рекомендуются из-за низкой надежности. Хранилище без RAID (JBOD) можно использовать только, если у вас есть вторая полная резервная копия архива.
Важно: используйте hot-spare диски или держите оперативный запас дисков того же объема на складе на случай отказа одного из HDD.
Немаловажным аспектом использования RAID является резервирование RAID-контроллера. Если используется аппаратный RAID, существует ли надежный план восстановления в случает отказа контроллера? Есть ли на складе идентичная модель? Возможно, стоит сразу использовать софтверный RAID, у которого не будет проблем с восстановлением на другой машине?
Желательно использовать сервера с двумя блоками питания, питающимися от разных фаз/вводов. Необходимо наличие ИБП. Если сервер/ИБП конструктивно может быть запитан только от одного источника, то для повышения надежности можно использовать специальный PDU с возможностью питания от двух источников.
Старая админская мудрость гласит, что использование RAID не является заменой резервному копированию. Вообще стандарт DICOM не поддерживает операций удаления из архива, поэтому уничтожения данных из-за ошибки оператора, как правило, можно не бояться. Однако существуют другие опасности, например, разрушение файловой системы, отказ нескольких дисков или физическое уничтожение сервера в результате пожара, затопления и т.п. серверного помещения. В таких случаях может спасти только настоящий бекап.
Для восстановления PACS нужно сохранять дамп БД и резервную копию файлов исследований. Особенностью DICOM в данном случае является то, что PACS, как правило, хранят каждый снимок отдельно, так что на диске будут лежать миллионы мелких файлов. В результате полный бекап десятилетнего хранилища может занять дни или даже недели. Возможно, для снимков оптимальной стратегией будет разово сделать полную копию и настроить инкрементальное резервное копирование, например, раз в сутки. Хорошей новостью является то, что файлы DICOM обычно неплохо сжимаются, поэтому бекап может занимать значительно меньше места, чем оригинал.
Несколько лет назад мы заводили для резервного копирования open source ПО Bacula и роботизированную ленточную (LTO) библиотеку. В 2022 году уже кажется, что исходя из совокупной стоимости владения и простоты администрирования для бекапа предпочтительно использовать обычный сервер с HDD. При этом желательно, чтобы архивная копия физически находилась как можно дальше от основного PACS на случай пожара: в другом корпусе, на другом этаже или хотя бы в другом помещении. Не стоит делать бекап на тот же сервер, где «живёт» PACS — это серьезно его «обесценивает».
Нужно помнить, что авария центрального хранилища может привести к приостановке лечебной деятельности, поэтому разумно завести PACS горячего резерва на отдельной физической машине. Основной PACS следует настроить на автоматическую отправку свежих снимков на резервный. В принципе такой «брат-близнец» может быть альтернативой резервному копированию. Если же бюджет не позволяет зеркалировать архив за всё время, можно держать в горячем резерве только свежие исследования, например за последний месяц. Т.к. клиентов обычно не так много, не обязательно держать настоящий балансер (типа HAProxy) на случай отказа — достаточно оповестить медицинский персонал, что есть резервный архив, которым они могут пользоваться, и завести его AE Title на всех локальных узлах.
Наконец, немаловажным элементом устойчивой эксплуатации является мониторинг. Помимо использования обычного шаблона мониторинга аппаратного обеспечения и ОС для PACS-сервера, следует обратить пристальное внимание на мониторинг сервиса PACS и его резерва (с помощью утилит отправки C-ECHO, см. ниже), свободного места, свободных inode (для Linux), специфических метрик используемой СУБД. Обязательно также настроить оповещения от диагностики дисков S.M.A.R.T. и RAID-контроллера. Резервное копирование также должно быть покрыто мониторингом.
Если модальности или сопутствующие системы поддерживают сбор метрик (через snmp или т.п.) их также стоит замониторить. В зависимости от тяжести аварийной ситуации стоит настроить алертинг вплоть до автоматического экстренного звонка на телефон дежурного сотрудника — например, отказ воздушного контура охлаждения МРТ может привести к кипению дорогостоящего жидкого гелия и сбросу его через аварийный клапан, что приведет к финансовым потерям и простою сканера.
Мониторинг может также служить подспорьем в планировании закупок (capacity planning), прежде всего HDD под хранилище. Для этого нужно организовать сбор метрик об объеме новой информации поступающей в неделю/месяц/год — можно экстраполировать график и заранее узнать, когда понадобятся новые диски.
Клиенты и утилиты
Просмотрщиков для DICOM очень много, упомянем некоторые:
Horos — открытый и бесплатный просмотрщик для Mac OS X;
OsiriX — популярный платный просмотрщик для Mac OS X, может работать как PACS, есть бесплатная Lite версия;
Weasis — открытый кроссплатформенный просмотрщик для Linux, Mac OS X и Windows; есть portable версия; может быть интегрирован в dcm4chee как веб-просмотрщик;
Oviyam 2 — HTML5 просмотрщик для web;
MultiVox DICOM Viewer — бесплатный отечественный просмотрщик для Windows;
MicroDicom — бесплатный для некоммерческого использования просмотрщик для Windows;
Vidar Dicom Viewer — просмотрщик DICOM исследований для Windows, Linux систем, есть бесплатная версия.
Сайт IDoImaging.com содержит большую подборку бесплатного софта медицинской визуализации.
dcm4che3 — открытый кроссплатформенный набор утилит для манипуляций с DICOM — например, миграции исследований по сети или мониторинга ответа C-ECHO;
DCMTK — открытий кроссплатформенный набор утилит и библиотек для DICOM.
Ещё почитать
- Сайт стандарта DICOM
- DICOM Standard Browser — удобная навигация по атрибутам
- Типы данных
- Basic DICOM Operations
- Глоссарий OTpedia
- PACS-сервер своими руками
- Серия постов «DICOM Tutorial» на сайте «DICOM is Easy»
- Introduction to DICOM
- Пьяных, О.С. Digital Imaging and Communications in Medicine (DICOM). A Practical Introduction and Survival Guide— Springer, 2008. ISBN: 978-3-540-74571-6